
Alors que de plus en plus de moteurs de rendus migrent vers le bindless texturing, votre codebase utilise peut-être encore des descriptors pour le binding de vos textures. Peut-être que vous devez maintenir la compatibilité avec d’anciennes APIs, hardware, ou simplement n’avez pas assez de temps pour mettre l’entiereté de votre codebase à niveau. Et même si vous faites du rendu bindless, il se peut que vous copiiez encore des descripteurs pour vos samplers.
En D3D12 il est commun de n’utiliser qu’une seule root signature pour tous vos shaders, avec un nombre de slots fixe pour vos textures. La gestion de vos ressources ressemble alors à celle que vous auriez avec D3D11. Cependant le problème principal avec cette approche est que si votre root signature autorise jusqu’à, par exemple, 64 SRVs (Shader Resource Views), mais n’en utilise que 2 pour votre shader, vous aurez à copier 62 null descriptors pour “rien”. En effet, par défaut il n’est pas autorisé d’avoir des descriptors invalides dans votre descriptor table.

Vous pourriez alors retrouver du code similaire à celui-ci:
const int MaxSRVsInTable = 64;
const int firstSlot = heap.AllocateSlots(MaxSRVsInTable);
for (int i = 0; i < MaxSRVsInTable; i++)
{
// If we have a SRV to bind, copy its descriptor
if (const SomeViewDataStructure* viewData = viewsPtrArray[i])
{
devicePTr->CopyDescriptorsSimple(1,
heap.GetCPUSlotHandle(firstSlot + i),
viewData->GetCPUDescriptor(),
D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV);
}
else // Copy a null descriptor
{
devicePTr->CopyDescriptorsSimple(1,
heap.GetCPUSlotHandle(firstSlot + i),
NullSRVDescriptorCPU,
D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV);
}
}Ce n’est pas très efficient car vous devez les copies un par un! Sur l’un des moteurs sur lesquels j’ai pû travailler, presque la moitié du temps du thread de rendu était passé dans ces copies de descriptors, c’est beaucoup.
Avez-vous remarqué que l’on passe toujours 1 comme NumDescriptors à CopyDescriptorsSimple ?
La première chose qui peut nous faire gagner beaucoup de temps, est de copier plusieurs descriptors à la fois. Mais ce n’est pas possible à moins de savoir quels slots sont bindés par le shader, peut-être que nos deux slots sont les numéros 5 et 62. Déterminer les intervalles où copier les null descriptors pourrait coûter aussi cher que de les copier un à un.
Première optimisation
Heureusement pour nous, le compilateur de shaders DirectX alloue les registres de façon à ce que les ressources utilisées soient concentrées dans les premiers emplacements, des trous n’apparaissent en réalité que si vous avez des accès conditionnels dans votre shader.
Basé sur cette observation, on peut optimiser pour un sous-cas: celui où les emplacements vides sont après les derniers utilisés.

Il est possible de déterminer facilement quel est le dernier emplacement utilisé par un shader via votre moteur ou en stockant la réflection du compilateur (de préférence dans vos assets) avec ID3D12FunctionReflection::GetResourceBindingDesc.
Puis, au lieu de créer un seul null descriptor au lancement de votre application, créez un tableau contigu de MaxSRVsInTable null descriptors. Cela vous permet alors de faire un seul appel à CopyDescriptorsSimple pour l’ensemble des emplacements restant, et de gagner un temps CPU précieux !
for (int i = 0; i < nbSrvSlotUsedByShader; i++)
{
// If we have a SRV to bind, copy its descriptor
if (const SomeViewDataStructure* viewData = viewsPtrArray[i])
{
devicePTr->CopyDescriptorsSimple(1,
heap.GetCPUSlotHandle(firstSlot + i),
viewData->GetCPUDescriptor(),
D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV);
}
else // Copy a null descriptor
{
devicePTr->CopyDescriptorsSimple(1,
heap.GetCPUSlotHandle(firstSlot + i),
NullSRVDescriptorCPU,
D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV);
}
}
// Copy the remaining null descriptors in a single API call, way, way faster!
if(const int remainingSlots = MaxSRVsInTable - nbSrvSlotUsedByShader)
{
devicePTr->CopyDescriptorsSimple(remainingSlots,
heap.GetCPUSlotHandle(firstSlot + nbSrvSlotUsedByShader),
NullSRVDescriptorsArray,
D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV);
}En appliquant cette optimisation sur les descriptors de SRVs, CBVs, UAVs and samplers, nous avons observé un gain d’environ 2ms sur notre thread de rendu, pour une scène d’environ ~2100 drawcalls !
⚠ Pour les descriptors utilisés par le shader, il est nécessaire que descriptors soient du bon type à moins d’avoir un matériel avec le resource binding tier approprié. Vous ne pouvez donc pas mélanger des descriptors d’une
Texture2Davec un d’uneTexture1D, ou UAV à la place de SRV.
Cette simple optimisation nous a fait gagner de précieuses millisecondes, mais peut-on faire mieux ?
Hardware tiers
Il se trouve que oui ! Bien que notre code soit désormais bien plus rapide, D3D12 nous permet de faire encore plus d’optimisations.
Selon la documentation:
In summary, to create a null descriptor, pass null for the pResource parameter when creating the view with methods such as
CreateShaderResourceView. For the view description parameterpDesc, set a configuration that would work if the resource was not null (otherwise a crash may occur on some hardware).
On Tier1 hardware (see Hardware Tiers), all descriptors that are bound (via descriptor tables) must be initialized, either as real descriptors or null descriptors, even if not accessed by the hardware, otherwise behaviour is undefined.
On Tier2 hardware, this applies to bound CBV and UAV descriptors, but not to SRV descriptors.
On Tier3 hardware, there’s no restriction on this, provided that uninitialized descriptors are never accessed.
Cela signifie qu’en fonction du hardware tier, il est possible d’ignorer entièrement cette copie de null descriptors !
Il suffit pour cela de vérifier le support des hardware tier avant d’activer notre prochaine optimisation. Pour cela, vous pouvez utiliser CheckFeatureSupportà l’initialisation de votre renderer.
D3D12_RESOURCE_BINDING_TIER resourceBindingTier = D3D12_RESOURCE_BINDING_TIER_1;
D3D12_FEATURE_DATA_D3D12_OPTIONS options;
if (SUCCEEDED(lDevice->CheckFeatureSupport(D3D12_FEATURE_D3D12_OPTIONS, &options, sizeof(options))))
{
resourceBindingTier = options.ResourceBindingTier;
}Plutôt que de faire un vérification dynamique, vous pourriez demander une configuration minimale de tier 2. Vous l’imposez même peut-être déjà implicitement via d’autres tiers. La matrice de support correspondante est disponible sur cette page wikipedia.
Aucun GPU lancé post 2015 et aucun CPU lancé post 2018 sont de Tier 1.
Le code de copie devient alors :
// Copy the remaining null descriptors unless hardware tier is high enough
if(resourceBindingTier >= 2)
if(const int remainingSlots = MaxSRVsInTable - nbSrvSlotUsedByShader)
{
devicePTr->CopyDescriptorsSimple(remainingSlots,
heap.GetCPUSlotHandle(firstSlot + nbSrvSlotUsedByShader),
NullSRVDescriptorsArray,
D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV);
}Notez que le tier 2 est requis pour cette optimisation avec les SRVs and samplers, et le tier 3 pour les UAVs et CBVs.
Dans le cadre de notre test (~2100 drawcalls), nous avons gagné 1ms de plus en temps CPU sur notre thread de rendu en ignorant toutes ces copies, soit un gain de 3ms comparé à la version d’origine.
Rétrofit pour les tiers inférieurs
Nous avons vu qu’il est possible d’obtenir de gros gains en ne réalisant pas la copie des null descriptors. Bien que cela soit possible pour les tiers supérieur, et si au lieu de simplement ne pas faire de copies on réutilisait la mémoire des emplacements vides pour le prochain drawcall ?
Pour cela, il suffit de s’assurer que l’on réserve le maximum d’emplacements qu’un shader peut avoir mais de n’allouer que ceux réellement nécessaires au drawcall. La raison pour laquelle nous devons tout de même réserver la mémoire et non pas simplement l’allouer est qu’il est nécesaire de s’assurer que la heap contient assez d’emplacements pour tous les descripteurs du drawcall, tel que défini par la root signature. Puis, avant d’envoyer la commandlist au GPU, on vient compléter les emplacements du dernier drawcall de chaque heap (ou non, si le tier hardware le permet) en copiant les null descriptors au lieu de le faire pour chacun des descriptors.
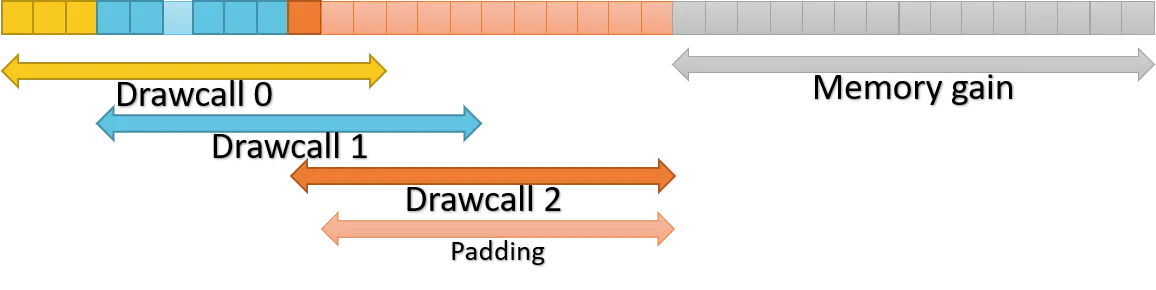
De cette façon, non seulement nous gagnons du temps CPU, mais également de la mémoire, et de façon plus importante de la bande passante !
Un piège courant
Il est nécessaire de s’assurer que les shaders n’accèdent pas aux emplacements que l’on ne réutilise ou ne remplit pas avec l’optimisation précédente. Bien que cela est la plupart du temps le cas lorsque le sampling est réalisé à l’intérieur du branchement (if), il existe un cas où ce n’est pas vrai.
Si vous compilez vos shaders avec le paramètre -all-resources-bound (qui est recommandé pour des raisons de performance ! Voir cette article by NVidia et ce post de blog de Microsoft), alors compilateur va partir du principe que toutes les ressources sont toujours bindées. Cela signifie que nbSrvSlotUsedByShader doivent être récupérés à partir du shader lui-même (par exemple via réflection) et non pas simplement ignorer la copie de certains des null descriptors. Par exemple, si votre shader utilise 5 SRVs, mais que le 4ème et 5ème sont optionnels, il est tout de même nécessaire de copier les null descriptors pour ces 2 slots, mais pas pour les MaxSRVsInTable - 5 restant.
C’est pourquoi je recommande fortement d’utiliser le DirectX debug layer et même d’activer la validation GPU car le debug layer à lui tout seul pourrait ne pas suffire à détecter si un descriptor est accédé ou non.
Notes: Les mesures de temps annoncées sont données pour une machine avec un Intel CPU i7-9700K @ 3.60GHz
